Webpack应该是我们常用的打包工具,它的主要作用是将多个JavaScript模块打包成一个或多个静态资源文件,以便在浏览器中加载和执行。
大致它会帮我们做到以下几点:
- 模块化支持:Webpack支持CommonJS、AMD、ES6等多种模块化规范,可以将多个模块打包成一个或多个静态资源文件,方便在浏览器中加载和执行。
- 代码压缩:Webpack可以对打包后的代码进行压缩和混淆,从而减小文件大小,提高页面加载速度。
- 资源优化:Webpack可以对图片、字体等资源进行优化,如压缩、合并、转换等,从而减小文件大小,提高页面加载速度。
- 代码分离:Webpack可以将应用程序代码和第三方库代码分离打包,从而减小文件大小,提高页面加载速度。
- 开发环境支持:Webpack可以在开发环境中提供热更新、代码检查、调试等功能,从而提高开发效率和代码质量。
接下来我将从0演示基于webpack的整个项目搭建与优化的过程。
目录
内容
实例剖析分包
剖析分包,目的在于合理控制页面内容的加载,尤其在控制首屏加载速度上的影响是重要的。接下来实例中会总是从2个角度关注,
1关注打包的情况, 2.关注实际代码加载的情况
- 先弄个仅简单的猫猫狗狗的js,dog和cat都import了shout.js。
shout.js如下:const str = `~~~~` export function shout(s) { console.log("The animal is shouting: ", s || str) }内容结构如下

webpack配置如下,先简单打个包const path = require('path'); module.exports = { entry: { cat: "./src/cat.js", dog: "./src/dog.js" }, output: { path: path.resolve(__dirname, 'dist'), filename: '[name].js', }, mode: "development" //"production","development","none" };打包情况,产生了cat和dog两个chunks
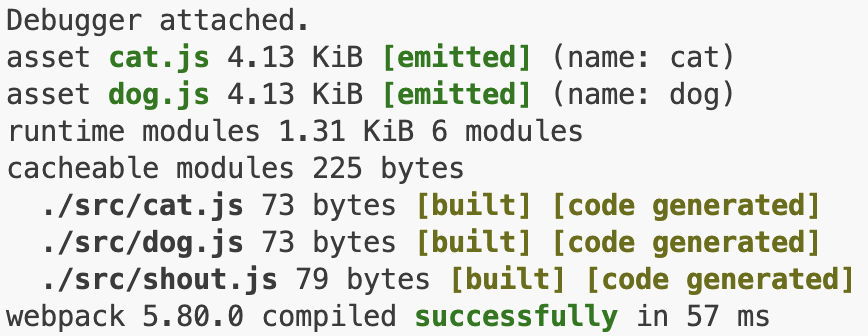
页面就script加载2条js代码

你首先会疑问,shout.js相关的chunk在哪里?这里我们需要了解splitChunks的默认基础配置。接下来我们逐个逐个去了解。
首先解决shout.js相关的chunk在哪里?
先关注chunks这个配制项, 它默认只提取异步加载的。而我们现在的加载不是异步的,如图:import shout from './shout.js'; shout("miaomiao~") console.log("cat js is coming")那我尝试将其改为异步加载的方式, 再看看变化:
shout.js修改import( "./shout.js" ).then(( {shout} )=>{ shout("miaomiao~") }); console.log("cat js is coming")打包结果, 可以看到,多了一个src_shout_js.js 1.18KiB出来。
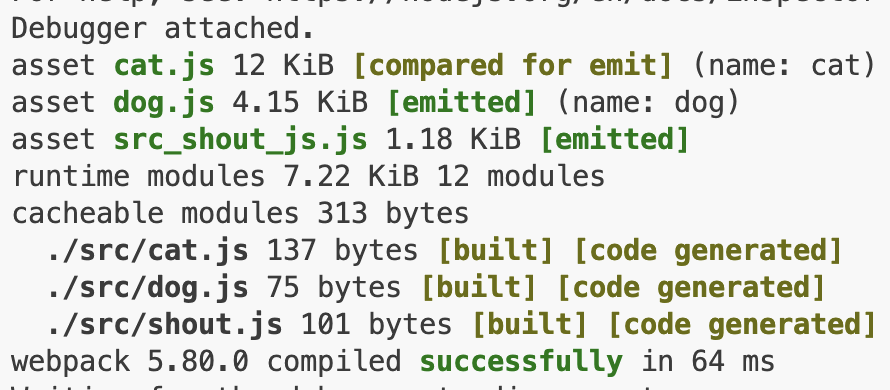
页面引用先只引用dog<body> <script src="./dist/dog.js"></script> <!-- <script src="./dist/cat.js"></script> --> </body>访问页面则只加载dog.js

若页面引用只引用cat<body> <!-- <script src="./dist/dog.js"></script> --> <script src="./dist/cat.js"></script> </body>访问加载了cat.js, src_shout_js.js。

很显然是因为cat.js的异步引用的原因,才导致了这个src_shout_js.js的出现。有一点需要注意,我们并没有手动在页面添加shout相关的script标签,那么它是如何加载的。我们看一下打包后的cat.js的源码:
eval执行插入

此处断点,先不执行后续的加载逻辑,页面只有cat.js
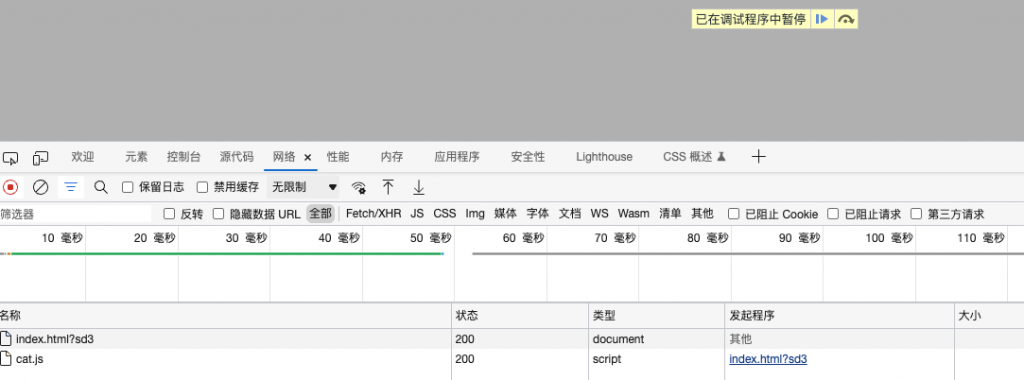
然后继续进行,__webpack_require__.e(chunkId)加载代码模块

此时页面才会加载shout.js的内容
看来webpack4中出现的splitChunks是可以帮我们做代码分片加载的。splitChunks具体的配置参数可以仔细去查阅一下splitChunks官网配置文档
着重说一下异步导入的意义的具体体现,webpack让我们能基于异步模式来导入内容,就意味着我们甚至可以基于特定条件来实现我们的代码按需导入。我们可以简单的测试一下。稍稍延迟下导入,setTimeout(()=>{ import( "./shout.js" ).then(( {shout} )=>{ shout("miaomiao~") }); }, 5000) console.log("cat js is coming")查看下网络请求
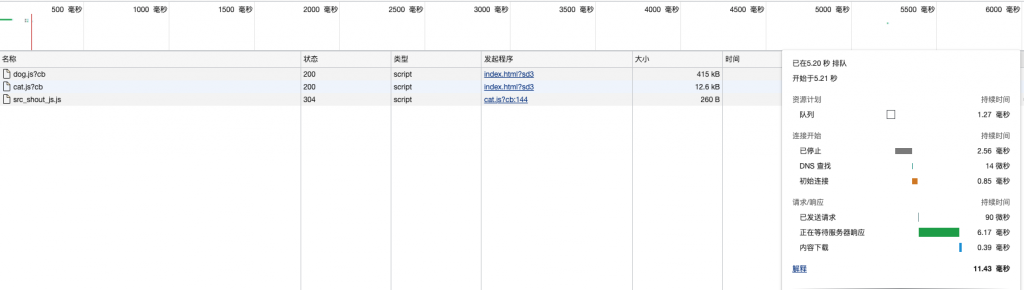
从上图你可以清楚看到几点
1-shout.js延时了5s才加载
2-shout.js的触发是cat.js
所以我们只需要合理的使用异步加载,就可以实现代码的按需加载。
控制打包内容
如果我们没可能“买台性能强劲的电脑”,那么我们就只能考虑减少要做的工作。
着重关注这几个配置项: test, exclue, include, noParse, ignorePlugin
- test, exclude和include是确定loader的规则范围
- noParse是不去解析但仍会打包到bundle中
- IgnorePlugin,它可以完全排除一些模块,被排除的模块即便被引用了也不会被打包进资源文件中
module.exports = { module: { rules: { test: /\.(js|jsx)$/, exclude: [/node_modules/, /static\/dist/], include: '/src/xxx' }, noParse: '/lodash/' } };对于一些由库产生的额外资源,我们其实并不会用到但又无法去掉,因为引用的语句处于库文件的内部。
比如,Moment.js是一个日期时间处理相关的库,为了做本地化它会加载很多语言包,占很大的体积,但我们一般用不到其他地区的语言包,这时就可以用IgnorePlugin来去掉。plugins: [ new webpack.IgnorePlugin({ resourceRegExp: /^\.\/locale$/, // 匹配资源文件 contextRegExp: /moment$/, // 匹配检索目录 }) ]
利用缓存
我们可以令Webpack将已经进行过预编译的文件内容保存到一个特定的目录中。当下一次接收到打包指令时,可以去查看源文件是否有改动,如没有改动则直接使用缓存即可,中间的各种预编译步骤都可以跳过。
这里说的利用缓存是指打包时充分利用缓存,加速打包。
Webpack 5引入了一个新的缓存配置项, webpack这里缓存有两种方式:一是基于内存;二是基于文件系统。内存不能持久,所以基于文件系统就是我们讨论的重点。
看下cache的相关参数列表
这里我们通过true或false控制的其实只是Webpack基于内存的缓存。
module.exports = {
// ...
cache: true,
};Webpack还支持另外一种基于文件系统的缓存,这种缓存机制必须要强制开启才会生效,开启的配置如下:
module.exports = {
// ...
cache: {
type: 'filesystem',
},
};开启后默认会产生存储cache的文件夹
缓存的使用是把两面刀,有利有弊。好处是加速打包,坏处是有时候不想缓存时,却被缓存了。所以我们一定要对于如何破除缓存有一定了解。
如何有效地利用文件系统缓存。Webpack提供了多种破除缓存的方法,分别是当以下内容变化时,都会破处缓存:

- 打包依赖(Build Dependencies)
- 缓存名称(Cache Name)
- 缓存版本(Cache Version)
未完,待续……
从无到有
- 创建项目文件夹
mkdir webpack-demo
因为是演示,所以会从0开始,而且越简单越明了,目的只在于演示原理。 - 我们就先从最核心的内容开始定义,做4件事:
- 源码文件夹
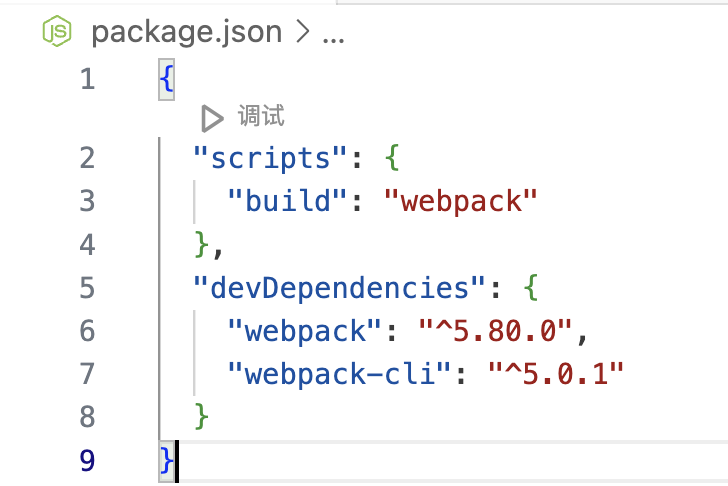
- webpack相关依赖安装
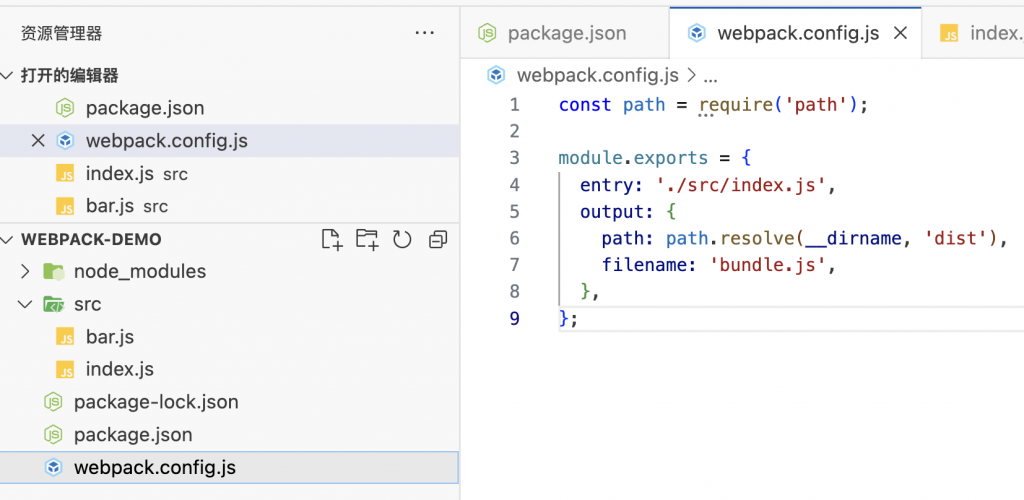
- 写个webpack配置文件
- 执行打包
npm run build
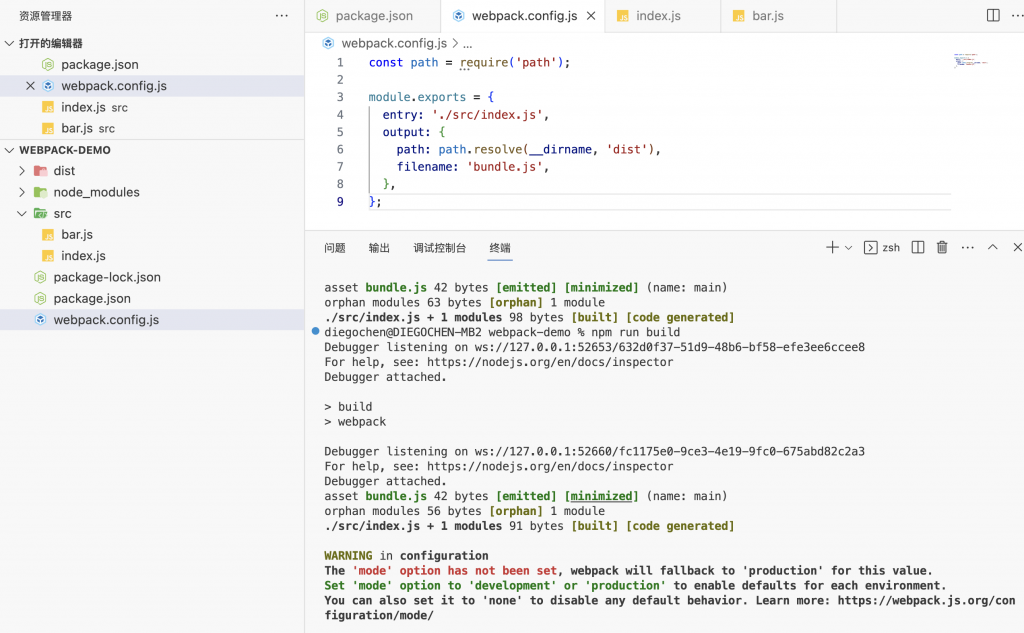
- 源码文件夹
- 于是我们就得到了dist文件里面的.bundle.js
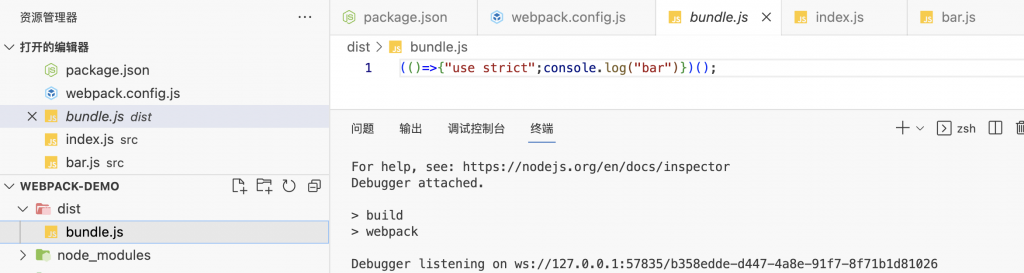
回头看下这个hello world做了些什么?
- 我们源码写了两个模块,
- 然后我们通过安装的webpack,
- 基于最简单的配置(指定源码入口和打包出口)
- 执行了一下打包命令
- 就产出了打包的文件bundle.js
这就是webpack干的事!
模式
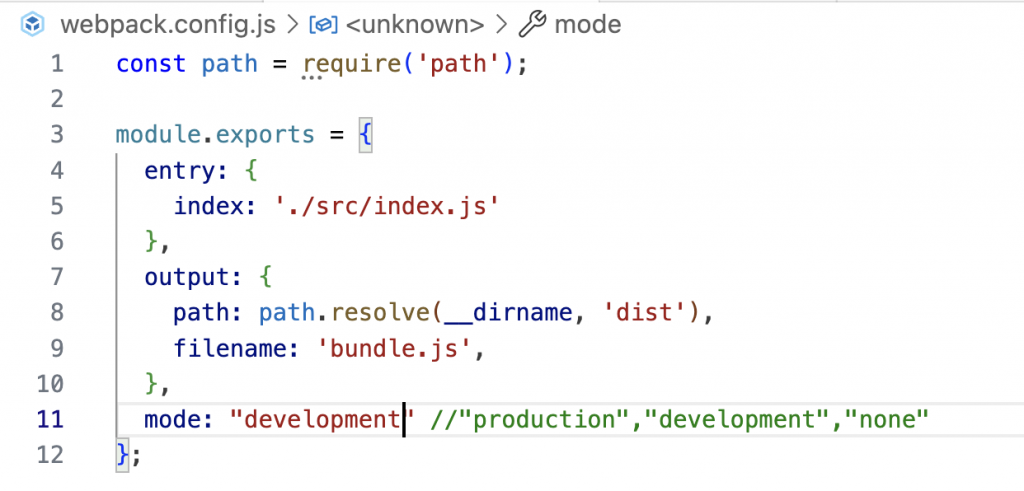
你可能上面的build图中看到有这段提示
WARNING in configuration
The 'mode' option has not been set, webpack will fallback to 'production' for this value.
Set 'mode' option to 'development' or 'production' to enable defaults for each environment.Webpack的配置文件中有一个mode选项,用于指定Webpack的构建模式。Webpack 4中加了的这一个mode配置项。mode选项有三个可选值:development、production和none。
-
development模式:该模式下Webpack会开启调试工具,生成的代码不会被压缩,同时会输出更多的调试信息,方便开发人员进行调试。

-
production模式:该模式下Webpack会开启各种优化功能,生成的代码会被压缩和混淆,同时会去除调试信息,从而减小文件大小,提高页面加载速度。

-
none模式:该模式下Webpack不会开启任何优化功能,生成的代码不会被压缩和混淆,同时会输出更多的调试信息,适用于一些特殊的构建需求。

入口
入口entry: 即告诉Webpack从哪里开始进行打包。
entry的配置可以有多种形式:
- 字符串
直接传入文件路径, 一切原材料的都将以它作为入口流入webpack。上面的示例正是如此。 - 数组
传入一个数组的作用是将多个资源预先合并,这样Webpack在打包时会将数组中的最后一个元素作为实际的入口路径。 如下:- 加个console.js
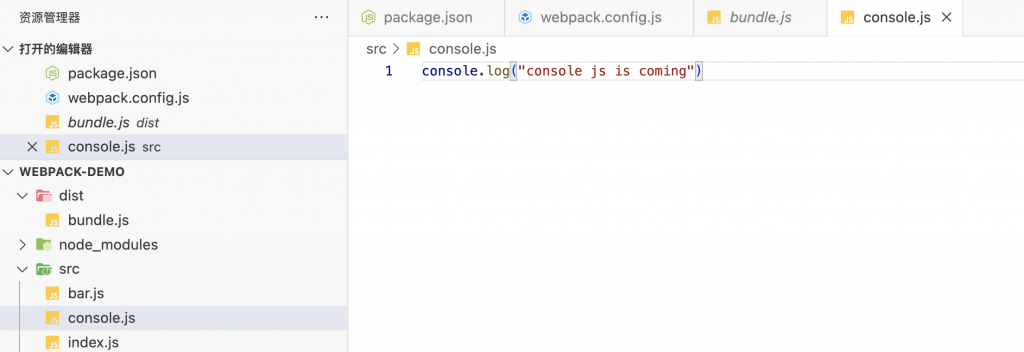
- 用数组定义entry
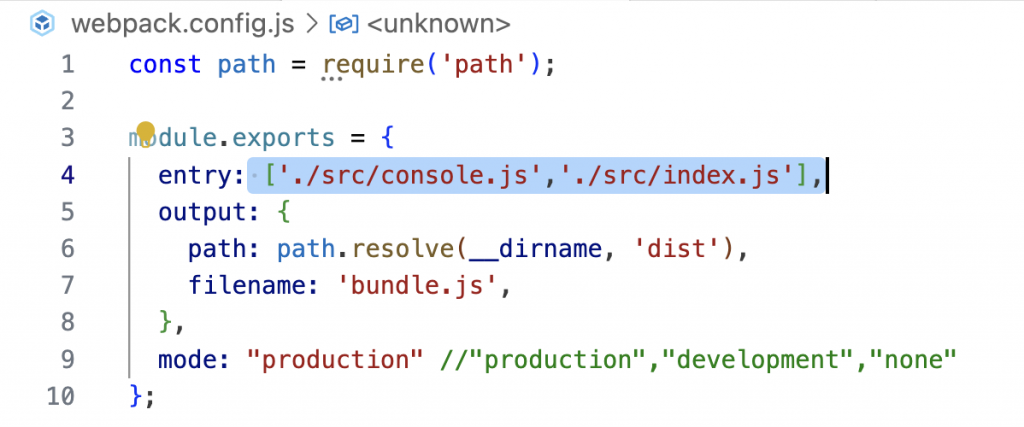
- 就会把console.js打包到bundle.js里面

- 加个console.js
- 对象
如果想要定义多入口,则必须使用对象的形式。
对象的属性名(key)是chunk name,属性值(value)是入口路径。 - 函数
其实非常简单,只要使匿名函数的返回值为上面介绍的任何配置形式即可。
出口
所有与出口相关的配置都集中在output对象里。
filename的作用是控制输出资源的文件名。
在多入口的场景中,我们需要为对应产生的每个bundle指定不同的名字。
output:{
filename: [name].js,
path: "...", //用来指定资源的输出位置
publicPath: "..." //则用来指定资源的请求位置
}这里在动态关联产出文件的名称时就有几个关键字可以用
| 关键字 | 作用与描述 |
|---|---|
| [name] | 当前chunk的名称 |
| [id] | 当前chunk的ID |
| [chunkhash] | 当前chunk的内容的hash |
| [contenthash] | 当前chunk单一内容的hash |
这几个作用在哪里呢?
- name和id都是相对chunk名称和id来设定的吧,所以基本是固定的。
- chunkhash和contenthash就会针对其中的内容来设定了,注意,敲黑板!这其实是说只要相关内容变换,这个hash值就会变化!, 意义在哪里呢?在于破除强缓存机制啊!
当浏览器访问一个网页时,会将一些静态资源(如图片、CSS、JavaScript等)缓存到本地,以便下次访问同一页面时可以直接从本地缓存中读取,从而提高页面加载速度和用户体验。
但是,当这些静态资源发生变化时,例如修改了CSS样式或JavaScript代码,浏览器会重新请求服务器获取最新资源。如果服务器返回的资源名称与之前缓存的资源名称不同,浏览器会认为这是一个新的资源,会重新缓存到本地。因此,当资源名称发生变化时,浏览器会重新请求服务器获取最新资源,而不是从本地缓存中读取。
顺带说一下吧。
浏览器缓存机制主要分为两种:强缓存和协商缓存。 - 强缓存:浏览器在第一次请求资源时,会将资源的过期时间(Expires)或最大缓存时间(Cache-Control)等信息存储到本地缓存中。
- 协商缓存:当强缓存失效时,浏览器会向服务器发送请求,询问服务器该资源是否有更新。服务器会根据资源的标识(如ETag或Last-Modified)来判断资源是否有更新,如果有更新,则返回最新资源,否则返回304状态码,告诉浏览器可以直接从本地缓存中读取资源。常见的协商缓存策略有ETag和Last-Modified。
可能这里还是需要提一下path和publicPath.
- path可以指定资源输出的位置,要求值必须为绝对路径
const path = require('path'); module.exports = { entry: './src/app.js', output: { filename: 'bundle.js', path: path.join(__dirname, 'dist') , //输出位置设置为工程的dist目录 }, }; -
publicPath则用来指定资源的请求位置
假设当前HTML地址为 https://example.com/app/index.html
异步加载的资源名为 0.chunk.js
publicPath: "" // 实际路径https://example.com/app/0.chunk.js
publicPath: "./js" // 实际路径https://example.com/app/js/0.chunk.js
publicPath: "../assets/" // 实际路径https://example.com/aseets/0.chunk.js
代码分片
实现高性能应用的重要的一点就是尽可能地让用户每次只加载必要的资源,对于优先级不太高的资源则采用延迟加载等技术渐进式获取,这样可以保证页面的首屏速度。代码分片是Webpack作为打包工具所特有的一项技术,通过这项技术,我们可以把代码按照特定的形式进行拆分,使用户不必一次加载全部代码,而是按需加载。
虽然代码分片可以有效降低首屏加载资源的大小,但同时会带来新的问题,比如我们应该对哪些模块进行分片、分片后的资源如何管理等,这些也是需要关注的。
首先看下我们如何分片吧。
- 通过入口的配置我们可以进行一些简单有效的代码拆分。
webpack入口时配置为两个入口entry:{ app: "./app.js", lib: ["lib-a", "lib-b"] }index.html中就用2条script
<script src="dist/app.js"></script> <script src="dist/lib.js"></script>
上面lib将绑定到全局对象的库统一分在了一起,但实际情况还会涉及具体业务内代码的分片。
-
同理对于多页面应用,我们也可以一个页面一个入口文件来分片。再按需加入公共依赖。但是这样去维护加载,想想得多麻烦呀。
-
CommonsChunkPlugin(CommonsChunkPlugin是Webpack 4之前内部自带的插件(Webpack 4之后替换为SplitChunks)。它可以将多个Chunk中公共的部分提取出来),
假设代码如下:

webpack配置如下:const webpack = require('webpack'); module.exports = { entry: { foo: './foo.js', bar: './bar.js', }, output: { filename: '[name].js', } };打包结果如下, 可以看到没有提取公共的react。
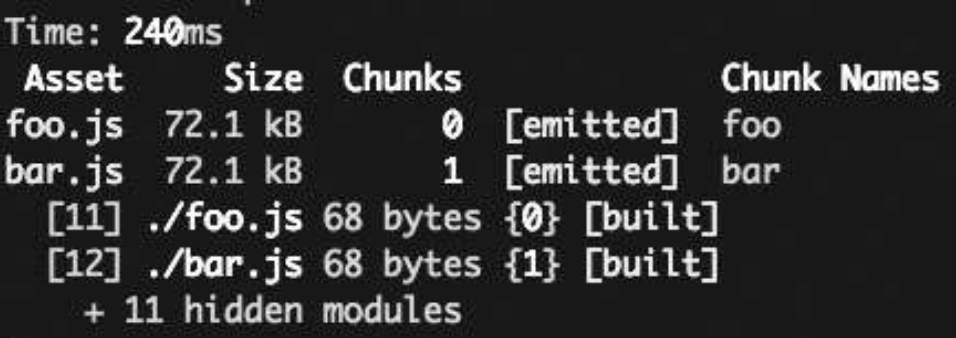
加上CommonsChunkPlugin后的webpack配置如下:const webpack = require('webpack'); module.exports = { entry: { foo: './foo.js', bar: './bar.js', }, output: { filename: '[name].js', }, plugins: [ new webpack.optimize.CommonsChunkPlugin({ name: 'commons', filename: 'commons.js', }) ], };打包结果如下,可以看到已经提取了命名为common.js的公共代码。那其实就是提取的公共的reactjs
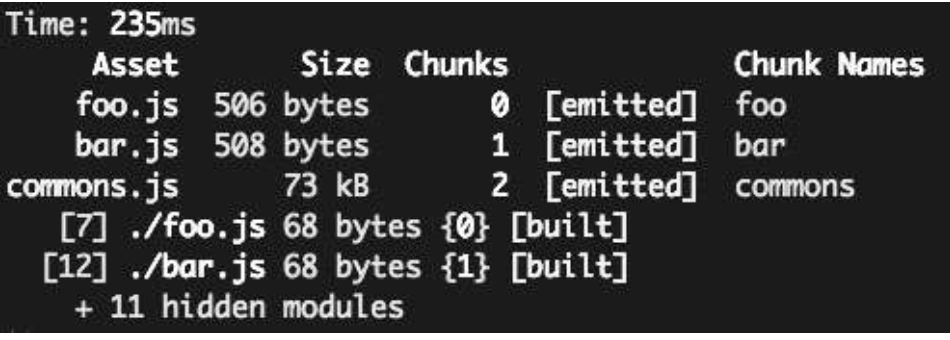
当然我们也可以按照前面所说的方式定义一个公共入口,里面指定公共依赖模块的名称:// webpack.config.js const webpack = require('webpack'); module.exports = { entry: { app: './app.js', vendor: ['react'], }, output: { filename: '[name].js', }, plugins: [ new webpack.optimize.CommonsChunkPlugin({ name: 'vendor', filename: 'vendor.js', }) ], };打包结果如下, 产出了vendor.js
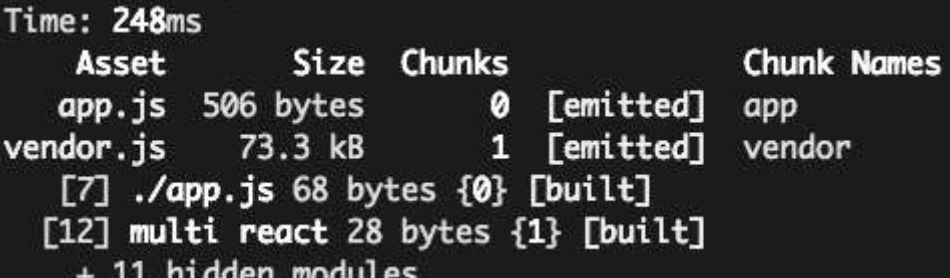
看看CommonChunksPlugin的配置项有哪些吧。// webpack.config.js const webpack = require('webpack'); module.exports = { ... plugins: [ new webpack.optimize.CommonsChunkPlugin({ name: 'vendor', //用于指定公共chunk的名字 filename: 'vendor.js', //提取后的资源文件名 chunks: ['a', 'b'], //范围,表示只会从a.js和b.js中提取公共模块 minChunks: 3, //引用要求-被引用次数。 只有该模块被n个入口同时引用才会进行提取 }) ], }; -
SplitChunks
optimization.SplitChunks(简称SplitChunks)是Webpack 4为了改进CommonsChunk-Plugin而重新设计和实现的代码分片特性。先看个例子:// webpack.config.js module.exports = { entry: './foo.js', output: { filename: 'foo.js', publicPath: '/dist/', }, mode: 'development', optimization: { splitChunks: { chunks: 'all', }, }, }; // foo.js import React from 'react'; import('./bar.js'); document.write('foo.js', React.version); // bar.js import React from 'react'; console.log('bar.js', React.version);打包结果如下, 可以看到splitChunks不需要特地配置公共项,它也把react抽离了出来
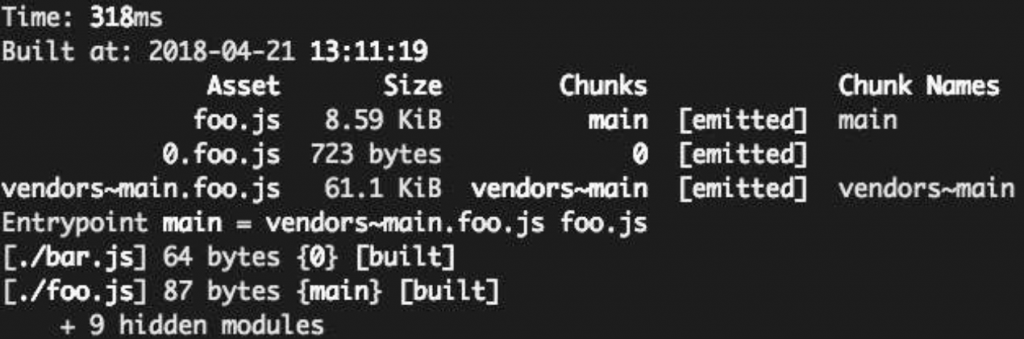
foo.js :foo内容 0.foo.js :foo涉及异步加载的内容 vendors~main.foo.js :公共模块内容关于splitChunks,我们先看看它的默认基础配置
- 提取后的chunk可被共享或者来自node_modules目录
- 提取后的JavaScript chunk体积大于20KB(压缩和gzip之前),CSS chunk体积大于50KB。
- 在按需加载过程中,并行请求的资源最大值小于等于30。
- 在首次加载时,并行请求的资源数最大值小于等于30。因为页面首次加载时往往对性能的要求更高,我们可将它手动设置为更低
splitChunks: { chunks: "async", minSize: 20000, minRemainingSize: 0, minChunks: 1, maxAsyncRequests: 30, maxInitialRequests: 30, enforceSizeThreshold:50000, cacheGroups: { vendors: { test: /[\\/]node_modules[\\/]/, priority: -10, }, default: { minChunks: 2, priority: -20, reuseExistingChunk: true, }, }, },我们着重看看其中的异步按需加载。它的意义在于什么呢?资源异步加载主要解决的问题是,当模块数量过多、资源体积过大时,可以延迟加载一些暂时使用不到的模块。
未完,待续……
0 条评论